Guest. Optimal Control
Given by: Asst. Prof. Gokhan Alcan
-
Demo: Cart-Pole Swing-Up
-
Constrained Optimal Control
1. Motivation
Section titled “1. Motivation”Optimization cost(time or frequency-domain). In the time domain, judge a closed-loop step response:
- Lower rise time bigger overshoot.
- Lower overshoot longer rise time.
method:
- Imposing additional constraints.
- Integral criteria let (reference - output), following common scalar measures how good a response is:
IAE: Integral of from 0 to . ITAE: Integral of from 0 to . ISE: Integral of from 0 to .
Balance tracking vs effort with a weighted sum:
What Optimization variables to choose
- Controllers: Pick a class(e.g. PID) and optimize its parameters. is a function of these parameters(evaluated by simulation); closed-loop stability conditions make the problem typically nonconvex.
- Control signals: Optimize directly. Awkward in continout time(function-space problem); So we just solve in discrete (sequence) time — back to finite-dimensional optimization.
2. Discrete-Time Optimal Control
Section titled “2. Discrete-Time Optimal Control”-
Optimization variable refers to the control inputs (such as the accelerator, brakes and steering angle of an autonomous vehicle) that we need to apply at each of the N time steps, ranging from 0 to N−1. Our task is to find the optimal sequence of control signals.
-
Cost function J: we want the lowest cost:
— Stage Cost: represents the immediate cost incurred at each intermediate time step k due to the state deviating from the target (for example, the car veering off course) or the control action being too forceful (for example, slamming the accelerator).
— Terminal Cost: indicates how far the system’s final state is from our true endpoint at the conclusion of the Nth step. This is typically used to ensure that the system converges stably.
s.t. is an abbreviation for ‘subject to’, meaning ‘provided that the following conditions are met’.
- System dynamics constraints (Physics/Dynamics): .
- Path Constraints This is a strict requirement that must be met at every intermediate point throughout the entire process (from k=0 to N−1).
Equational constraints (e.g. dynamics, terminal goal, grasp constrains) Inequality constraints (e.g. bounds, obstacles, frictions, cones ).
3. Dynamic Programming & Bellman’s Principle
Section titled “3. Dynamic Programming & Bellman’s Principle”- Main idea of Dynamic Programming: always remember the answers to the sub-problems you have already solved.
- If a problem can be broken down into smaller sub-problems, those can be broken into smaller ones still, and some sub-problems overlap — then you have a DP problem.
“An optimal policy has the property that no matter what the previous decisions (i.e., controls) have been, the remaining decisions must constitute an optimal policy with regard to the state resulting from those previous decisions.” — Bellman, 1957

Applying this principle reduces the number of candidates for the optimal solution: once we know the optimal sub-path from b to e, any a→e trajectory through b must reuse it.
4. iLQR
Section titled “4. iLQR”We are given three things:
- An initial state (start position)
- A guessed control sequence (initial “plan”)
- Known dynamics (physics model)
Without optimization, nominal trajectory (usually bad)
Running cost
- Penalizes deviation from goal along the way.
- Penalizes large control effort (energy).
- Typically:
Terminal cost = Boundary Condition
- Penalizes where we end up.
- Often lare weight “reach to the goal!”.
- Typically:
- At the last step , there are no more decisions.
- So the “cost-to-go” from is simply
- This is — the value function seed.
- The backward pass starts here and walks back to .
The Big idea: One big optimization can be solved as many small ones, one step at a time.
Recall: exact DP
Section titled “Recall: exact DP”From the Bellman recursion:
Why we can’t solve this directly:
- and are functions over the whole continuous state–action space.
- A grid over scales as — curse of dimensionality.
- No closed form for general nonlinear and .
iLQR: model only near a guess
Section titled “iLQR: model QQQ only near a guess”Start from a nominal rollout (Step 0):
Define perturbations around it:
Approximate as a quadratic in centered at .
Valid only near the nominal — we will rebuild the model after every trajectory update.
Second-order Taylor at
Section titled “Second-order Taylor at (xˉk,uˉk)(\bar{x}_k, \bar{u}_k)(xˉk,uˉk)”Drop the constant (it does not affect ). The remaining gradient + Hessian terms:
All blocks are partial derivatives of , evaluated at the nominal — so they are just numbers/matrices, not functions.
1. Coefficients via chain rule
Section titled “1. Coefficients via chain rule”Recall . Differentiating and writing :
where are partials of the stage cost; are dynamics Jacobians at ; and are inherited from the next step’s value (backward pass).
:
:
:
2. Minimize Q for local Policy
Section titled “2. Minimize Q for local Policy”For each , find the best Since is quadratic in , the minimum is at the stationary point. Take the gradient w.r.t. :
Set it to zero (assuming ):
Solve for :
Split the constant from the -dependent part:
Implementation practice
Section titled “Implementation practice”Regularize before inverting. Far from the optimum, can be ill-conditioned or even indefinite. A direct inverse then produces huge or completely wrong steps. Levenberg–Marquardt fix:
- : full Newton step (fast).
- : gradient descent (safe).
- Trust-region schedule: on rejected step, on accepted step.
3. Value Update (Backward Prop)
Section titled “3. Value Update (Backward Prop)”Plug back into the quadratic expansion to update the Value function approximation () for step :
- These are passed to step
Algorighm Overview
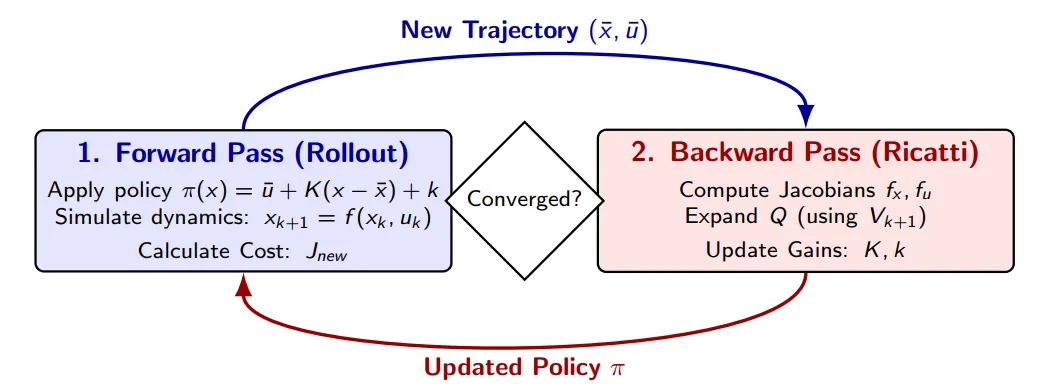
- Forward Pass / Rollout
- Apply control policy: use to compute control input.
- is the reference control value from the previous iteration.
- is the state feedback, to fix the difference between actual state and desired state .
- is the Feedforward term, used to adjust the control reference as a whole.
- Simulate dynamics: according to , calculate the Roolout on time.
- Calculate cost: , is the cost of new trajectory.
- Backward Pass (Ricatti)
In this step, the algorithm works backwards from the end of the trajectory to the start, using the Bellman equation and the Riccati equation to optimise the policy:
- Compute Jacobians: at every timestep of ths trajectory, calculate and . (Locally linearization)
- Expand Q: by using the next timestep motion cost , perform a quadratic Taylor expansion of the current Q-function
- Update Gains: compute the feed fowrard and feedback gains.
- Convergence test
- Difference between new/old trajectory is small enough? ()
- Or the feedback gain is close to 0.
- None convergence? then update the policy then proceed forward pass.
* Local Optima: As a Newton-method variant, it converges to a local minimum. Good initialization is a key.
* Model Requirement: The backward step strictly requires partial derivatives of the model (f_x, f_u)
* Speed: Very fast for smooth dynamics.